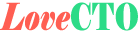 LoveCTO
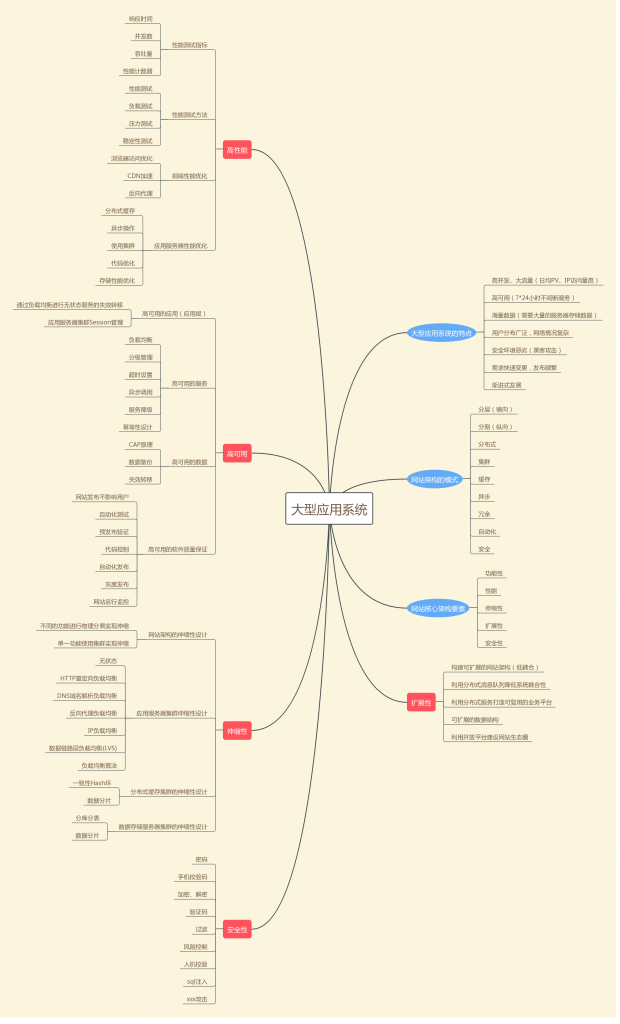
LoveCTO大型应用系统的特点
- 高并发、大流量(日均PV、IP访问量高)
- 高可用(7*24小时不间断服务)
- 海量数据(需要大量的服务器存储数据)
- 用户分布广泛,网络情况复杂
- 安全环境恶劣(黑客攻击)
- 需求快速变更,发布频繁
- 渐进式发展
网站架构的模式
- 分层(横向)
系统一般分为应用层、服务层、数据层。
- 应用层:复杂具体业务和视图展示,如APP客户端、WAP、WEB页面等。
- 服务层:为应用层提供服务支持,如API网关、产品服务、用户服务、订单服务等。
- 数据层:提供数据存储访问服务,如数据库、缓存、文件、搜索引擎等。
在实践中,大的分层结构内部还可以继续分层。
- 分割(纵向)
可以对各个层相对独立的业务或功能模块进行分割。
- 分布式
常用的分布式方案:分布式应用和服务、分布式静态资源、分布式数据和存储、分布式计算、分布式配置、分布式锁、分布式文件。
- 集群
分布式将分层和分割后的模块独立部署,但对于用户访问集中的模块,还需要将这些独立部署的服务器集群化,即多台服务器部署相同的应用构成一个集群,通过负载均衡设备共同对外提供服务。
- 缓存
浏览器缓存、CDN、反向代理、本地缓存、分布式缓存。
- 异步
异步架构是典型的生产者消费者模式。
异步特性:提高系统可用性、加快网站响应速度、消除并发访问高峰。
需要注意:异步方式处理业务可能会对用户体验、业务流程造成影响、需要网站产品设计方面的支持。
- 冗余
冷备份、热备份、灾备数据。
- 自动化
发布的过程自动化、自动化代码管理、自动化测试、自动化安全检测、自动化部署、自动化监控、自动化报警、自动化失效转移、自动化失效恢复、自动化降级、自动化资源分配。
- 安全
密码、手机校验码、加密、验证码、过滤、风险控制、人机校验。
网站核心架构要素
- 功能性
- 性能
- 可用性
- 伸缩性
- 扩展性
- 安全性
高性能
- 性能测试指标
- 响应时间。应用执行一个操作所需要的时间,包括从发出请求到最后响应数据所需要的时间。
| 常用系统操作 | 响应时间 |
|---|---|
| 打开一个网站 | 几秒 |
| 数据库查询一条记录(有索引) | 十几毫秒 |
| 机械磁盘一次寻址定位 | 4毫秒 |
| 机械磁盘顺序读取1M数据 | 2毫秒 |
| SSD磁盘顺序读取1M数据 | 0.3毫秒 |
| 远程redis读取一个数据 | 0.5毫秒 |
| 内存中读取1M数据 | 十几微秒 |
| JAVA程序本地方法调用 | 几微秒 |
| 局域网网络传输2KB数据 | 1微秒 |
- 并发数。系统能够同时处理请求的数目,反映了系统的负载特性(网站系统用户数>>网站在线用户数>>网站并发用户数)。
- 吞吐量。单位时间内系统处理的请求数量,体现系统的整体处理能力。TPS(每秒事务数)、HPS(每秒http请求数)、QPS(每秒查询数)。
系统吞吐量、系统并发数、以及响应时间的关系可以形象地理解为高速公路的通行状况:吞吐量是每天通过收费站的车辆数,并发数是高速公路上正在行驶的车辆数,响应时间是车速。车辆很少时,车速很快,但是通过收费站的车辆也少。随着高速公路上车辆的增多,车速受到轻微影响,通过收费站的车辆增多。随着车辆不断增加,车速越来越慢,高速公路越来越堵,通过收费站的车辆不增反降。如果车流量继续增加,任何偶然因素都会导致高速全部瘫痪,车走不动,高速公路成了停车场。
- 性能计数器。描述服务器和操作系统性能的一些数据指标,如System Load、对象与线程数、内存使用、CPU使用、磁盘和网络I/O等指标。
- 性能测试方法
- 性能测试
- 负载测试
- 压力测试
- 稳定性测试
- 前端性能优化
- 浏览器访问优化。减少http请求数(合并css、合并js、合并图片等)、使用浏览器缓存(增量更新缓存)、启用压缩(服务端压缩,客户端解压缩、减少传输数据量)、CSS存放在页面上面、JS放到页面最下面、减少cookie传输(静态资源独立域名访问,避免请求静态资源时发送cookie,减少cookie的传输次数)。
- CDN加速。
- 反向代理。
- 应用服务器性能优化
- 分布式缓存。优先考虑使用缓存优化性能,考虑脏读、缓存可用性(缓存雪崩)、缓存预热、缓存穿透(采用布隆过滤器或缓存空值设置TTL)。
- 异步操作。任何可以晚点做的事情都应该晚点做。使用消息队列,消息队列具有削峰填谷的作用。常用的消息队列RocketMq、ActivitMq、RabitMq,常用的消息队列规范JMS、AMQP。
- 使用集群。
- 代码优化。多线程(将对象创建为无状态对象、使用局部对象、并发访问资源时使用锁)、资源复用(尽量减少那些开销很大的系统资源的创建和销毁,比如数据库连接、网络通信连接、线程、复杂对象等,使用池技术)、数据结构(使用合理高效的数据结构)、垃圾回收。
- 存储性能优化。机械硬盘 VS 固态硬盘、B+树 VS LSM树、RAID VS HDFS。
高可用
高可用性HA(High Availability)指的是通过尽量缩短因日常维护操作(计划)和突发的系统崩溃(非计划)所导致的停机时间,以提高系统和应用的可用性。HA系统是目前企业防止核心计算机系统因故障停机的最有效手段。
- 高可用的应用(应用层)
- 通过负载均衡进行无状态服务的失效转移
- 应用服务器集群Session管理。Session复制、Session绑定、Cookie记录Session、分布式Session。
- 高可用的服务
– 负载均衡
– 分级管理(核心应用和服务使用更好的硬件、运维响应上针对核心服务要更为迅速、服务部署进行必要隔离避免故障的连锁反应)。
– 超时设置
– 异步调用
– 服务降级。拒绝服务(拒绝低优先级的调用,减少服务调用并发数,确保核心应用正常使用;或者随机拒绝部分请求调用,节约资源,让另一部分请求成功,避免要死大家一起死的惨剧)、关闭功能(关闭部分不重要的服务或者关闭服务内部部分不重要的功能)。
– 幂等性设计
- 高可用的数据
保护企业的数据就是保护企业的命脉,保证数据存储高可用的手段主要是数据备份和失效转移机制。
- CAP原理。数据持久性存储、备份,保证数据的可访问性;CAP原理认为,一个提供数据服务的存储系统无法同时满足数据一致性(Consistency)、数据可用性(Availibility)、分区耐受性(Partition Tolerance)这三个条件。数据强一致/数据用户一致/数据最终一致。
- 数据备份。冷备(难度低但不能保证数据最终一致同时也不能保证数据可用性)、热备(异步热备方式、同步热备方式)。
- 失效转移。
- 高可用的软件质量保证
- 网站发布。发布过程中不影响用户使用使用。
- 自动化测试。
- 预发布验证。(预发布服务器是一种特殊用途的服务器,它和线上的正式服务器唯一不同的就是没有配置在负载均衡服务器上,外部用户无法访问)。
- 代码控制。主干开发分支发布、分支开发主干发布。
- 自动化发布。
- 灰度发布。(部分服务器发布新版本,其余服务器保持老版本)
- 网站运行监控。用户行为日志采集(服务端日志收集,客户端浏览器日志收集,埋点)、服务器性能监控、运行数据报告、系统报警、失效转移、自动优雅降级。
伸缩性
- 网站架构的伸缩性设计
– 不同的功能进行物理分离实现伸缩。数据库从应用服务分离、缓存从应用服务分离、静态资源从应用服务分离、纵向分离(分层后分离,业务处理流程上不同的部分分离部署,实现系统伸缩性)、横向分离(业务分割后分离,将不同业务模块分离部署,实现系统的伸缩性)。
– 单一功能使用集群实现伸缩。
- 应用服务器集群伸缩性设计
应用服务器应该设计成无状态的。负载均衡是网站必不可少的基础技术手段。
- HTTP重定向负载均衡。HTTP重定向服务器是一台普通的应用服务器,其唯一的功能就是根据用户的HTTP请求计算一台真实的WEB服务器地址,并将该WEB服务器地址写入HTTP重定向响应中(响应状态码为302)返回给用户浏览器,浏览器自动重新请求实际的物理服务器,完成访问。HTTP302重定向优点是简单,缺点是可能被搜索引擎判断为SEO作弊,降低搜索排名。
- DNS域名解析负载均衡。大型网站总是部分使用DNS域名解析作为第一级负载均衡手段,分发到同样提供负载均衡服务的内部服务器。
- 反向代理负载均衡。反向代理服务器转发请求在HTTP协议层面,因此也叫应用层负载均衡。
- IP负载均衡。
- 数据链路层负载均衡。LVS。
- 负载均衡算法。轮询、加权轮询、随机、最少连接、原地址散列。
- 分布式缓存集群的伸缩性设计
一致性Hash环。
- 数据存储服务器集群的伸缩性设计
根据不同的应用场景进行设计。
扩展性
伸缩性:系统能够通过增加(减少)自身资源规模的方式增加(减少)自己计算处理事务的能力。
扩展性:对现有系统影响最小的情况下,系统功能可持续扩展或提升的能力。
- 构建可扩展的网站架构。低耦合的系统更容易扩展,低耦合的模块更容易复用,低耦合的系统设计会让开发过程和维护变得更加轻松和容易管理。
- 利用分布式消息队列降低系统耦合性。事件驱动框架、分布式消息队列。
- 利用分布式服务打造可复用的业务平台。
- 可扩展的数据结构。
- 利用开放平台建设网站生态圈。
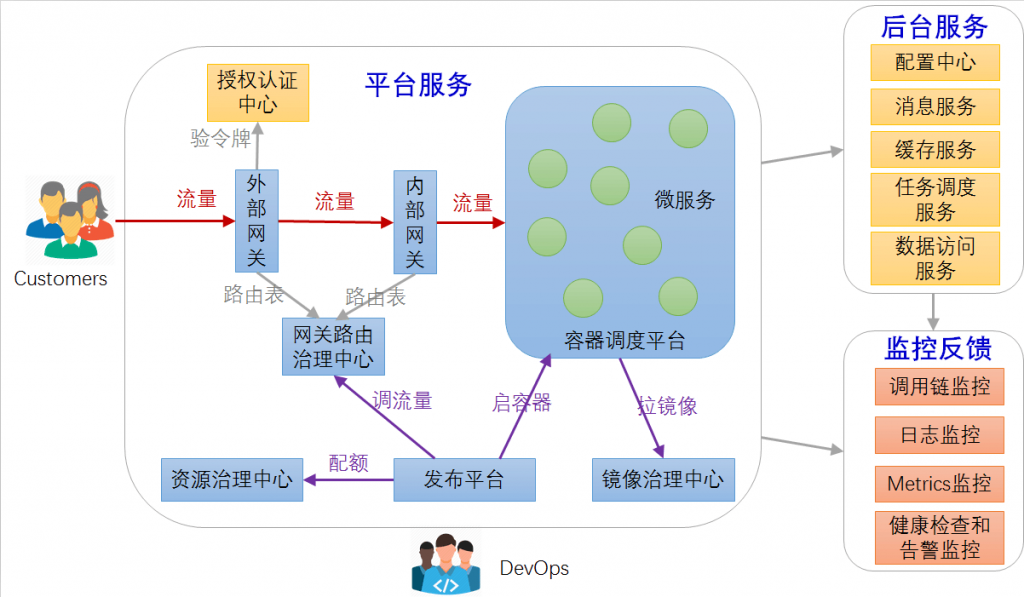
VIP
虚拟IP(VIP)技术是实现HA的一种方式。用数据库/调度器举个例子,两台数据库服务器功能完全一致,平常只有一台机器对外提供服务,另一台机器作为热备,当这台机器出现故障时,自动动态切换到另一台热备的机器。
虚拟IP就是一个未确定分配给真实主机的IP,也就是说对外提供数据库服务器的主机除了有一个真实IP(管理IP)外还有一个虚IP(应用IP),使用这两个IP中的任意一个都可以连接到这台主机,所有项目中数据库链接一项配置的都是这个虚IP,当服务器发生故障无法对外提供服务时,动态将这个虚IP切换到备用主机。
VIP的实现原理主要是靠TCP/IP的ARP协议。因为ip地址只是一个逻辑地址,在以太网中MAC地址才是真正用来进行数据传输的物理地址,每台主机中都有一个ARP高速缓存,存储同一个网络内的IP地址与MAC地址的对应关系,以太网中的主机发送数据时会先从这个缓存中查询目标IP对应的MAC地址,会向这个MAC地址发送数据。操作系统会自动维护这个缓存。这就是整个实现的关键。
自动实现VIP飘移切换的软件或应用:Heartbeat(功能强大但安装配置相对繁杂)、Keepalived(部署和使相对简单)。
LVS
LVS(Linux Virtual Server)即Linux虚拟服务器,是由章文嵩博士主导的开源负载均衡项目,目前LVS已经被集成到Linux内核模块中。
LVS可以让系统做到易扩展和高可用。
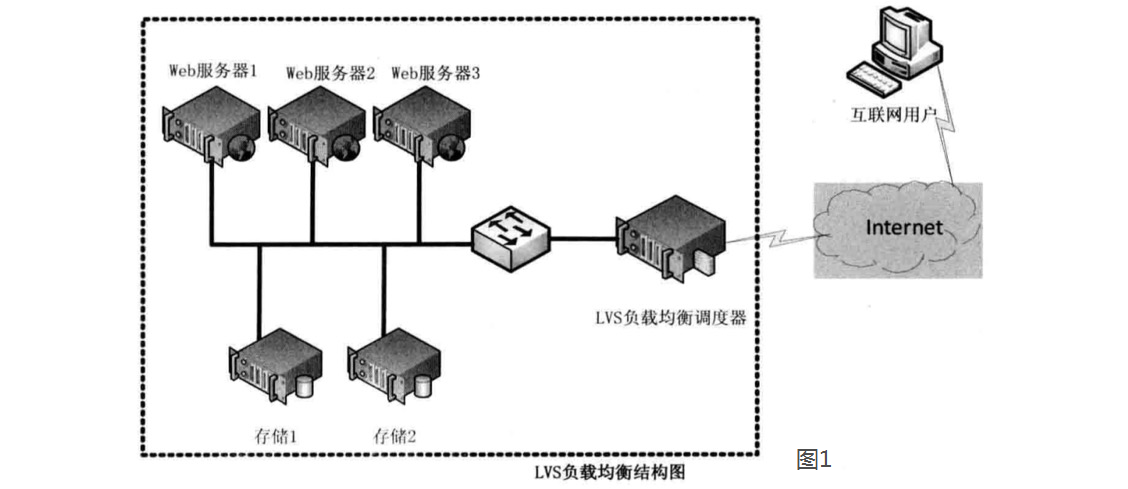
LVS有三种工作模式,分别是NAT、TUN、DR。
- NAT
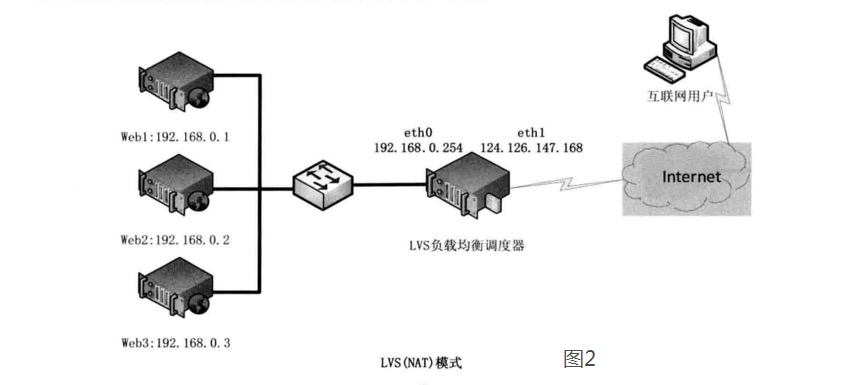
NAT(Network Address Translation)即网络地址转换。
用户将请求发送至124.126.147.168,此时LVS将根据预设的算法选择后端的一台真实服务器(192.168.0.1~192.168.0.3),将数据请求包转发给真实服务器,并且在转发之前LVS会修改数据包中的目标地址以及目标端口,目标地址与目标端口将被修改为选出的真实服务器IP地址以及相应的端口。
真实的服务器将响应数据包返回给LVS调度器,调度器在得到响应的数据包后会将源地址和源端口修改为VIP及调度器相应的端口,修改完成后,由调度器将响应数据包发送回终端用户。
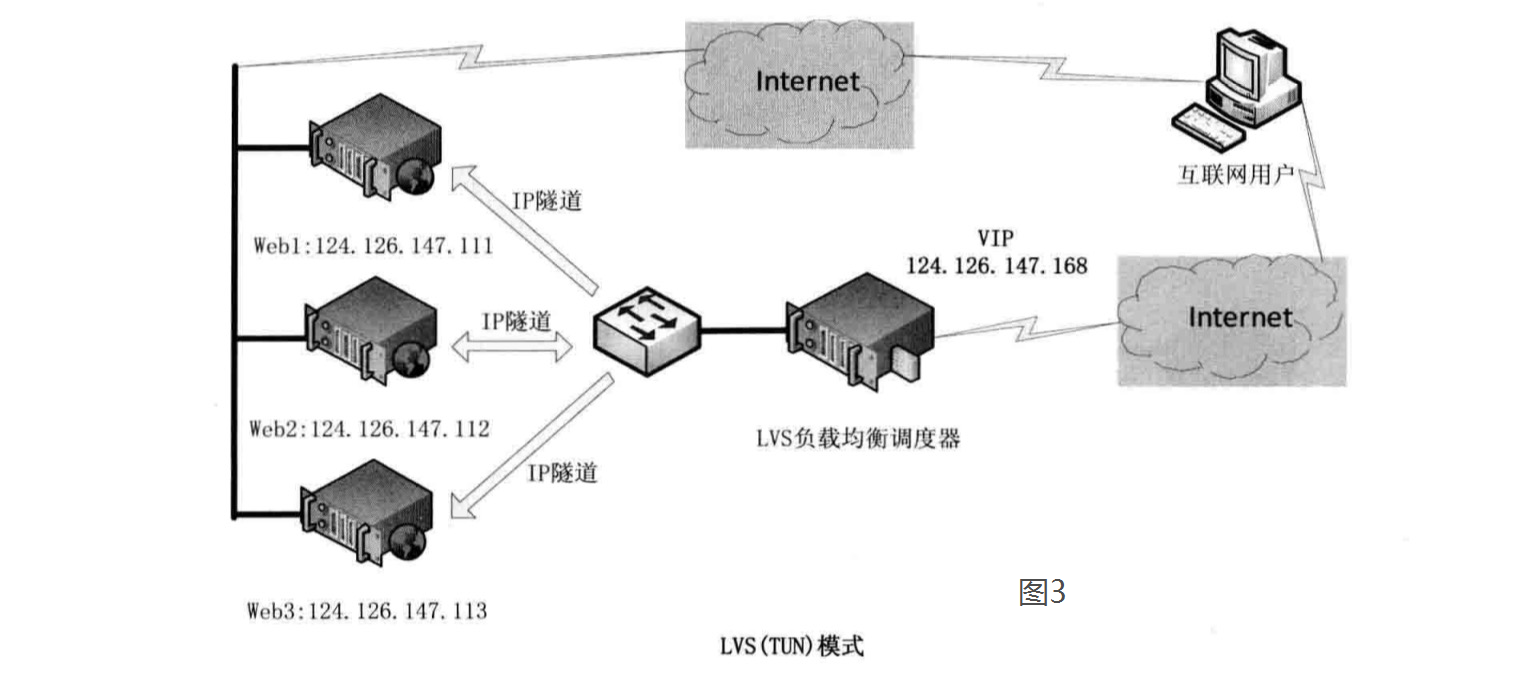
- TUN
在NAT模式的集群环境中,由于所有的数据请求及响应的数据包都需要经过LVS调度器转发,如果后端服务器的数量较多,则调度器就会成为整个集群环境的瓶颈。
一般情况下,数据请求包往往远小于响应数据包的大小。TUN模式的思路是把请求与响应数据分离,让调度器仅处理数据请求,而让真实服务器响应数据包直接返回给客户端。
IP隧道(IP tunning)是一种数据包封装技术,它可以将原始数据包封装并添加新的包头(内容包括新的源地址及端口、目标地址及端口),从而实现将一个目标为调度器的VIP地址的数据包封装,通过隧道转发给后端的真实服务器(Real Server),通过将客户端发往调度器的原始数据包封装,并在其基础上添加新的数据包头(修改目标地址为调度器选择出来的真实服务器的IP地址及对应端口),LVS(TUN)模式要求真实服务器可以直接与外部网络连接,真实服务器在收到请求数据包后直接给客户端主机响应数据。TUN模式客户端能感知到后端服务器的存在。
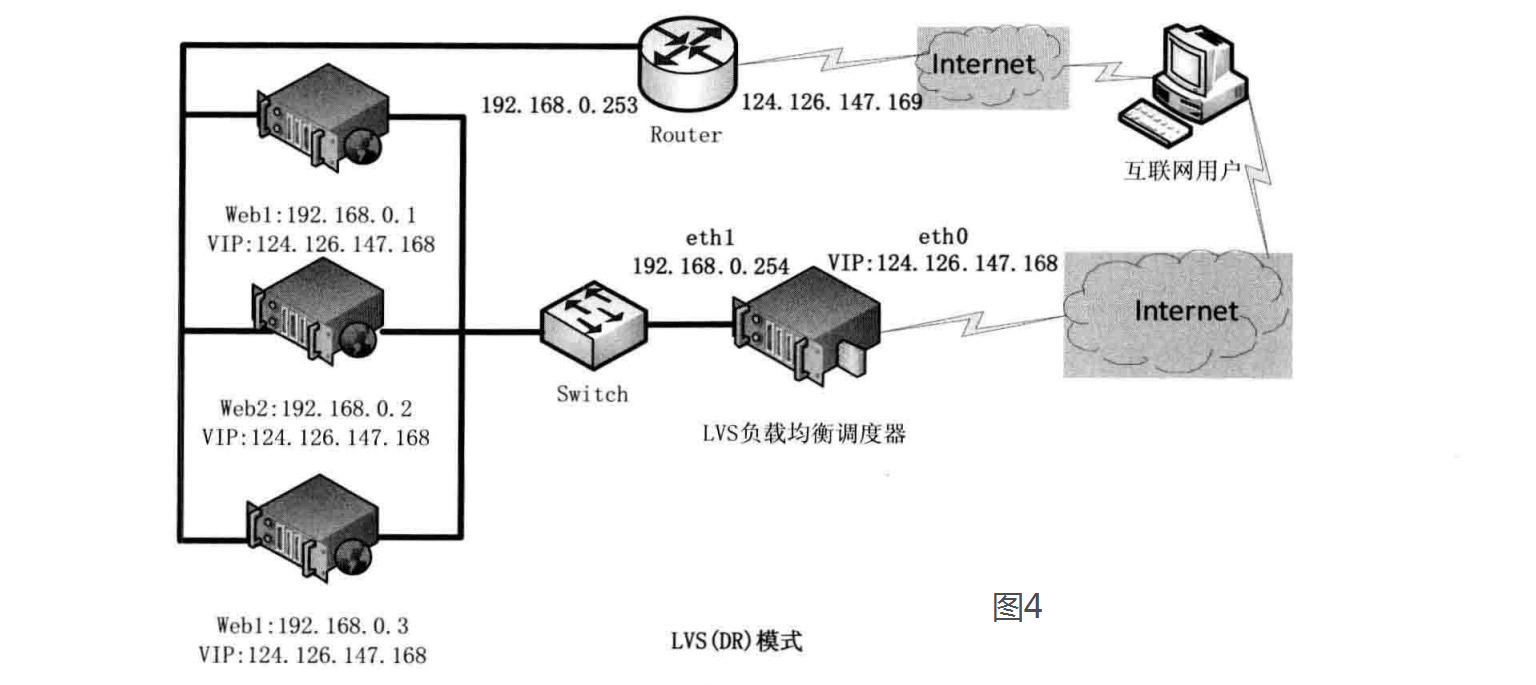
- DR
在TUN模式下,由于需要在LVS调度器与真实服务器之间创建隧道连接,这同样会增加服务器的负担。
该模式中LVS依然仅承担数据的入站请求以及根据算法选出合理的真实服务器,最终由后端真实服务器负责将响应数据包发送返回给客户端。与隧道模式不同的是,直接路由模式(DR模式)要求调度器与后端服务器必须在同一个局域网内,VIP地址需要在调度器与后端所有的服务器间共享,因为最终的真实服务器给客户端回应数据包时需要设置源IP为VIP地址,目标IP为客户端IP,这样客户端访问的是调度器的VIP地址,回应的源地址也依然是该VIP地址(真实服务器上的VIP),DR模式客户端是感觉不到后端服务器存在的。
由于多台计算机都设置了同样一个VIP地址,所以在直接路由模式中要求调度器的VIP地址是对外可见的,客户端需要将请求数据包发送到调度器主机,而所有的真实服务器的VIP地址必须配置在Non-ARP的网络设备上,也就是该网络设备并不会向外广播自己的MAC及对应的IP地址,真实服务器的VIP对外界是不可见的,但真实服务器却可以接受目标地址VIP的网络请求,并在回应数据包时将源地址设置为该VIP地址。调度器根据算法在选出真实服务器后,在不修改数据报文的情况下,将数据帧的MAC地址修改为选出的真实服务器的MAC地址,通过交换机将该数据帧发给真实服务器。整个过程中,真实服务器的VIP不需要对外界可见。
分库分表
此处用订单举例,通常一个订单包括:
– 订单ID
– 用户ID
– 预订时间
– 商户ID/供应商ID
我们针对订单进行分库分表,要从几个角度进行考虑:
- 用户:查询订单列表、查询订单详情。
- 商户:查询销售订单列表、查询订单详情。
- 平台:订单数据报表、订单数据分析、订单详情。
- 从利于用户查询的角度出发,那么按照用户ID(如按照用户ID取模/hash)进行分库分表是个不错的选择,这样每一个用户的查询都能在同一个数据节点上查询到用户的所有订单信息。
- 从利于商户查询的角度出发,那么按照商户ID(如按照商户ID取模/hash)进行分库分表是个不错的选择,这样每一个商户的查询都能在同一个数据节点上查询到商户的所有订单信息。
- 从平台查询的角度出发,平台有数据分析、数据统计、订单处理等需求,按照时间维度进行分库分表是个不错的选择,如按照年度进行分库分表。
- 从订单详情的查询角度出发,用户、商户、平台都有订单详情查询的需求,按照订单号取模/hash进行分库分表是不错的选择。
如何同时满足各方的查询需求?
把订单存储系统划分为核心订单存储子系统、用户订单存储子系统、商户订单存储子系统、时间周期订单存储子系统。每个订单号在4个子系统中确保最终一致性
- 核心订单存储子系统。这是订单的主存储(按照订单ID进行分库分表),订单的写操作都在这个子系统完成,订单详情查询可以在该系统进行查询,该系统的数据发生改变都会异步按照分库分表策略复制到其他存储子系统,从而达到最终一致性。
- 用户订单存储子系统。这是面向用户的订单存储(按照用户ID进行分库分表),用户侧的任何查询都针对该系统,该系统的数据是从核心订单存储子系统异步复制而来。
- 商户订单存储子系统。与用户订单存储子系统类似,按照商户ID进行分库分表,该系统的数据是从核心订单存储子系统异步复制而来。
- 时间周期订单存储子系统。按照时间维度进行分库分表,该系统的数据是从核心订单存储子系统异步复制而来。
4个子系统的数据确保最终一致性,异步复制和分库分表策略使用中间的DDL层进行逻辑处理,对上层透明。这样一来同一个订单,在整个存储系统中会有4份,一方面解决了各方的查询需求提升性能,另一方面4个子系统分布在不同的服务器,从而达到了冗余灾备的目的。